Flume在大数据生态中的数据采集实践与应用
在大数据技术生态中,数据采集是整个数据处理流程的基石,它负责从各种分散、异构的数据源中高效、可靠地收集数据,并将其汇聚到中央存储或处理系统中。Apache Flume作为一个高可用、高可靠、分布式的海量日志采集、聚合和传输系统,在这一环节扮演着至关重要的角色。本文将以技术博客的形式,探讨Flume的核心概念、架构设计及其在实际大数据项目中的应用实践。
一、Flume概述:数据流的可靠“搬运工”
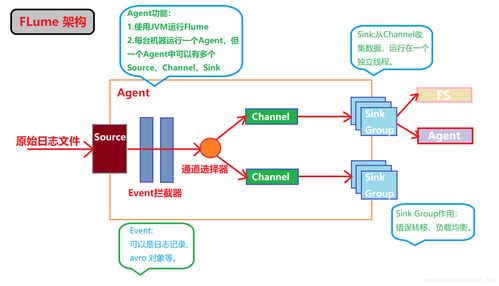
Apache Flume的设计初衷是为了解决大规模日志数据的实时采集问题。其核心思想是将数据流(Data Flow)抽象为“事件”(Event),并通过由“源”(Source)、“通道”(Channel)和“汇”(Sink)构成的“代理”(Agent)进行传输。这种清晰的架构使得Flume能够灵活配置,适应从简单单点采集到复杂、多层级的分布式采集场景。
二、核心组件深度解析
- Source(源):负责从数据源消费数据,并将其封装为事件。Flume提供了丰富的Source类型,支持从文件(如
Exec Source执行命令输出)、目录(Spooling Directory Source监控目录新增文件)、网络端口(NetCat Source,Syslog TCP/UDP Source)乃至Kafka(Kafka Source)等系统接收数据。 - Channel(通道):作为事件的临时存储区,连接Source和Sink。它提供了数据的缓冲能力,确保在Sink处理速度跟不上时数据不会丢失。常用的Channel包括基于内存的
Memory Channel(性能高,但宕机会丢数据)和基于文件的File Channel(可靠性高,速度稍慢)。 - Sink(汇):负责从Channel中取出事件,并将其传输到下一个目的地或最终存储库。常见的目的地包括HDFS(
HDFS Sink)、HBase(HBaseSink)、另一个Flume Agent(Avro Sink)或消息系统如Kafka(Kafka Sink)。
三、架构设计与高级特性
一个典型的复杂数据流可能涉及多个Flume Agent,形成多级流(Multi-hop Flow)或扇入/扇出流(Fan-in / Fan-out Flow)。例如,多个前端服务器的Agent可以将日志汇聚到一个中央聚合Agent,再由其写入HDFS,这体现了扇入流。
Flume的可靠性体现在其事务性的数据传递机制(基于Channel)和可配置的容错与负载均衡(例如在Sink组中设置多个Sink实现故障转移或负载均衡)。通过拦截器(Interceptor)链,用户可以在事件传输过程中进行简单的ETL操作,如添加时间戳、过滤特定事件或进行简单的格式转换。
四、实战应用:从配置到问题排查
1. 配置实例:一个将本地日志目录数据采集到HDFS的Agent配置示例片段如下:`properties
agent1.sources = src1
agent1.channels = ch1
agent1.sinks = sink1
agent1.sources.src1.type = spooldir
agent1.sources.src1.spoolDir = /var/log/app_logs
agent1.sources.src1.channels = ch1
agent1.channels.ch1.type = file
agent1.channels.ch1.checkpointDir = /data/flume/checkpoint
agent1.channels.ch1.dataDirs = /data/flume/data
agent1.sinks.sink1.type = hdfs
agent1.sinks.sink1.hdfs.path = hdfs://namenode:8020/flume/events/%Y-%m-%d/
agent1.sinks.sink1.hdfs.filePrefix = logs-
agent1.sinks.sink1.channel = ch1`
2. 性能调优与监控:需根据数据量调整Channel容量(capacity)、事务容量(transactionCapacity)以及HDFS Sink的滚动策略(按时间、大小或事件数量)。通过集成JMX可以监控各项指标,如Channel的当前大小、Source/Sink的成功/失败事件计数。
3. 常见问题:
* 数据重复:在采用File Channel且Sink未成功提交事务时,重启后可能重发。需确保Sink目的地(如HDFS)的写入是幂等的,或通过业务逻辑去重。
- 内存溢出:使用
Memory Channel且数据突发流量大时易发生。可切换为File Channel,或增加堆内存并调整垃圾回收策略。
- HDFS Sink小文件问题:过于频繁的文件滚动会产生大量小文件。应合理配置
hdfs.rollInterval,hdfs.rollSize,hdfs.rollCount参数,在延迟、文件大小和数量间取得平衡。
五、与Kafka的协作模式
在现代Lambda或Kappa架构中,Flume常与Kafka协作。一种常见模式是使用Flume作为“生产者”,将数据采集并推送至Kafka主题(通过Kafka Sink),再由下游的流处理框架(如Spark Streaming、Flink)或另一个Flume Agent进行消费。这结合了Flume在采集端的稳定性和Kafka在高吞吐、分布式消息缓冲方面的优势。
###
Apache Flume以其稳定、灵活的特性,成为了大数据数据采集层的一个经典选择。尽管在极致的实时性要求下,可能面临与更轻量级或定制化方案的竞争,但其在日志类、文件类数据向HDFS/HBase等系统迁移的场景中,依然发挥着不可替代的作用。深入理解其原理、合理设计数据流并做好监控调优,是保障大数据管道稳定高效运行的关键。
---
本文为技术博客分享,旨在梳理Flume的核心应用,具体配置与优化需结合实际生产环境。
如若转载,请注明出处:http://www.antscloudsec.com/product/72.html
更新时间:2026-06-19 18:51:17