大数据实战 基于Flink+Kafka的互联网日志实时收集与计算方案
在当今的互联网业务中,用户行为、系统运行、网络请求等每时每刻都在产生海量的日志数据。这些数据蕴含着巨大的价值,是进行业务监控、用户行为分析、性能优化和智能决策的基石。因此,构建一个高效、稳定、可扩展的日志实时收集与计算系统,已成为企业数据驱动战略的核心环节。本文将介绍一个经典的、在业界广泛应用的简单而有效的实时大数据处理方案。
一、 方案核心架构概述
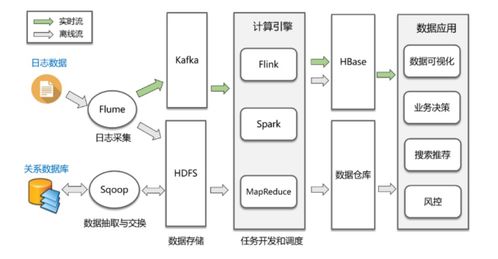
本方案采用业界成熟的Lambda架构思想,构建一个轻量级的实时数据处理流水线。其核心目标是实现从日志产生、到实时收集、再到快速计算与服务的端到端低延迟处理。主要组件包括:
- 数据源(Log Source): 指各类Web服务器(如Nginx、Tomcat)、应用程序、移动端APP等产生的原始日志文件或日志流。
- 实时收集层(Collection Layer): 负责从各个分散的源头高效、可靠地采集日志数据,并将其汇聚到中央消息队列。这里我们选用Apache Flume或Filebeat作为采集Agent。它们轻量、高效,支持断点续传,能实时监控日志文件的变化并将新数据发送出去。
- 消息缓冲队列(Message Queue): 作为系统的“流量洪峰缓冲池”和“解耦器”。收集层的数据首先被推送到这里,以平衡数据生产与消费的速度差异,并提高系统的鲁棒性。Apache Kafka是本方案的理想选择,它具有高吞吐、可持久化、分布式和容错的特性,非常适合日志流场景。
- 实时计算引擎(Stream Processing Engine): 这是方案的核心,负责从Kafka中实时消费数据,并执行复杂的转换、聚合、分析和过滤逻辑。我们选用Apache Flink。相比其他流处理框架(如Storm、Spark Streaming),Flink提供了真正的流处理语义(低延迟、高吞吐)、精确一次(Exactly-once)的容错保证,以及丰富的API(DataStream API),非常适合需要复杂事件处理和状态管理的实时分析任务。
- 存储与输出层(Sink Layer): 经过Flink处理后的结果,需要被存储下来以供查询或直接推送到下游服务。常见的输出目标包括:
- 实时仪表盘/告警系统: 将聚合后的指标(如每分钟PV/UV、错误率、API响应时间)实时推送到Elasticsearch + Kibana或Grafana,用于可视化监控和设置阈值告警。
- 在线服务数据库: 将用户画像标签、实时排行榜等结果写入Redis或HBase,供在线业务系统(如推荐系统、风控系统)低延迟调用。
- 离线数仓: 为了支持历史数据回溯和更复杂的批处理分析,原始日志或轻度聚合后的数据也可以被写入HDFS或数据湖(如Iceberg),进入离线数仓(如Hive)的范畴。
二、 一个典型的分析服务场景:实时流量大屏
假设我们需要为电商网站搭建一个实时流量监控大屏,核心指标包括:总访问量(PV)、独立访客数(UV)、各API接口的请求量与平均耗时、地域分布、热门商品点击流等。
数据处理流程如下:
- 日志生成与收集: Nginx服务器上配置JSON格式的访问日志。Filebeat Agent部署在每台服务器上,监控日志文件,并将新的日志行实时发送到Kafka的
raw<em>nginx</em>logTopic中。 - 数据接入与解析: Flink作业从Kafka的
raw<em>nginx</em>logTopic消费原始日志字符串。在Flink中,我们使用DataStreamAPI,首先对每行日志进行解析(Parse),将其从JSON字符串转换为结构化的Java/Python对象(包含字段如:timestamp, url, method, status, responsetime, userid, ip, user_agent等)。 - 实时计算与聚合:
- PV统计: 直接对解析后的所有日志事件进行滚动窗口计数(例如,每5秒计算一次过去1分钟的PV)。使用Flink的
TumblingWindow。
- UV统计: 基于
user_id(或对IP+User-Agent进行去重标识)进行去重计数。这里需要使用Flink的KeyedStream和状态(State)来管理窗口内的唯一用户集合,或使用HyperLogLog等概率数据结构进行近似统计以节省内存。
- API性能分析: 以
url和method为Key进行分组,在滑动窗口内计算每个API的请求次数、平均response_time、95分位响应时间以及错误(如status>=500)次数。
- 地域分析: 在流中调用IP地址库查询服务(或使用本地库),将
ip字段转换为省份、城市信息,然后按地域进行聚合统计。
- 热点商品追踪: 通过过滤和分析访问商品详情页(如URL包含
/product/)的日志,实时统计不同商品ID的点击量,并输出Top N列表。
- 结果输出与服务: 将上述各个聚合计算的结果流,分别写入不同的Sink:
- PV/UV、API性能等时间序列指标,写入Elasticsearch。Kibana配置对应的仪表盘,即可实现秒级更新的可视化图表。
- 实时热门商品Top N列表,写入Redis的Sorted Set,供前端大屏直接调用展示。
- 原始明细日志或宽表数据,可以同时写入Kafka的另一个Topic,供下游其他实时作业消费,或由Flink同步写入HDFS作为离线备份。
三、 方案优势与特点
- 低延迟与高吞吐: Kafka+Flink的组合能够轻松应对每秒百万级别的日志处理,端到端延迟可控制在秒级甚至毫秒级。
- 高可靠与容错: Kafka保证数据不丢失,Flink的Checkpoint机制保证了计算状态的精确一次(Exactly-once)处理语义,整个管道在节点故障时能自动恢复。
- 高可扩展性: 每个组件(Kafka, Flink)都是分布式的,可以通过增加节点来线性提升系统的处理能力。
- 架构解耦: 日志收集、消息队列、实时计算、存储展示各层职责清晰,通过标准接口(如Kafka Topic)连接,便于独立开发、维护和扩容。
- 技术栈成熟: 所采用的均为Apache顶级开源项目,社区活跃,文档丰富,有大量生产实践案例可供参考。
四、
本方案——以 Filebeat/Flume(采集) → Kafka(缓冲) → Flink(计算) → ES/Redis(存储服务) 为核心的数据流水线,提供了一个完整、高效且易于实施的互联网日志实时处理蓝图。它不仅能满足实时监控和告警的需求,更能为实时推荐、风控、个性化营销等高级分析服务提供源源不断的实时数据燃料。企业可以根据自身的数据规模和技术储备,从处理核心业务日志开始,逐步迭代和扩展此架构,最终构建起强大而灵活的企业级实时数据能力。
如若转载,请注明出处:http://www.antscloudsec.com/product/46.html
更新时间:2026-02-27 19:38:22